
Let’s face it – facial recognition technology is here to stay, and those with skin in the game are looking for ways to make use of it effectively and responsibly.
In 2012, the Google X laboratory announced a breakthrough that stunned the world: their artificial intelligence models had learned to correctly identify cats on YouTube.
After having studied just a few thousand YouTube thumbnails, these models could acquire new skills. It was prime example of just how far AI models had clawed forward.
They weren’t starting from scratch, though. This development in feline facial recognition was built upon decades of prior growth with another goal in mind. The quest to correctly identify human faces, both their existence in a frame and the specific individual to which they belong, was already well underway.
Over the last 10 years, AI technology has developed immense processing power, allowing it to absorb vast amounts of data in a short amount of time.
This, combined with highly sophisticated databases of visual information, has enabled facial recognition to move from identifying a species, such as a cat, to identifying the slightest nuance in a person’s appearance.
Let’s look at the beginnings of facial recognition technology, how it works, and where it’s headed.
What is facial recognition technology?
Facial recognition is a way of identifying or confirming your identity using your face. Facial recognition systems can be used to identify people in photos, videos, or in real-time.
Facial recognition has historically worked like other forms of “biometric” identification such as speech recognition, the irises of your eyes, or fingerprint identification.
Fingerprint data, for example, is gathered and analyzed for identifying markers. A newly found fingerprint can then be evaluated against this database for matching markers.
Facial recognition works in the same way. A computer analyzes image data and looks for a very specific set of markers within it – everything from a person’s head shape to the depth of their eye sockets.
A database of facial markers is created, and an image of a face that shares a critical threshold of similarity from database indicates a possible match. This is the basic principle behind all types of facial recognition, from unlocking your iPhone by scanning your face, to intercepting known shoplifters as they enter a store.
That worked well enough for relatively simple jobs, like figuring out where faces were within a photo, but to identify a particular face as matching a photograph of the same person? That turned out to be a bit more difficult.
Facial Recognition Technology Software and Algorithms
Several methods have been developed to enable accurate facial recognition, and they all begin with the collection of images and videos of people’s faces.
The computer must be trained to read the geometry of a face and identify specific facial landmarks. One system has up to 68 landmark points on a human face, localizing regions around the eyes, brows, nose, mouth, chin, and jaw.
This requires a set of rules general enough to include a wide range of facial types but narrow enough to exclude paintings and clothes-store mannequins.
Here are a couple more parts of the grander solution.
Gradients
The algorithm compares every image pixel’s brightness to the brightness of the pixels around it, creating a map of changing pixel intensity. A complex network of multi-directional, brightness gradients is then stored in coded form on the computer.
This is compared to an existing database of gradients to answer a series of questions, beginning with:
- Is this skin?
- If yes: do the surrounding pixel gradients indicate facial segments?
- If an eye: what is the eye color?
This process continues until all the facial features have been analyzed—from the location, size, and depth of the eyes to the precise anatomy and texture of the nose and so on.
Relative lighting attributes tend to hold true between shots, while objective lighting is much more variable — but even with this and other techniques, widely varying lighting conditions are still a point of difficulty for many modern facial recognition systems.
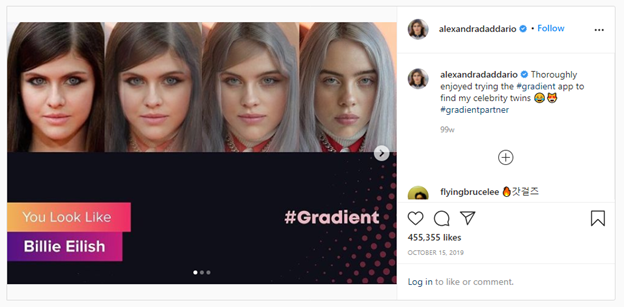
For example, this algorithm is used by the Gradient app to match your selfie with a celebrity, showing a transition between your face and theirs with a gradient morphing effect, but with varying degrees of success.
Projection
Another approach has to do with the projection of a 2D photo onto a 3D model, like a cylinder. Wrapping a face around a third dimension can often reveal forms of symmetry and distinguishing characteristics that are much harder to find in a flat and static image.
Once the image preparation has been completed, the system “encodes” the face, or collapses its most distinguishing characteristics and patterns to a smaller, simplified file that exists solely to do cross-checking with other encoded faces.
When shown a photograph of Leonardo DiCaprio, for example, this sort of system would first wrap and analyze the photo in various ways to generate an encoded version. It then compares that encoded face against a collection of encoded faces on file – Leo from Romeo and Juliet, The Great Gatsby, Django Unchained, and Once Upon a Time in Hollywood, to name a few iterations.

(Courtesy: Den of Geek)
It’s these stored faces that are the basis of comparison for finding facial matches, and it’s these stored files that can be pre-associated with information like names and addresses.
Even with these techniques, though, creating fast and accurate processes for comparing two faces and determining whether they are similar enough to be deemed the same person has been a challenge.
Deep Learning in Facial Recognition Technology
The field of facial recognition and identification didn’t really take off until developers stopped trying to design the perfect matching algorithm and instead embraced deep learning—the use of a mathematical model that mimics the brain’s neural networks to build understanding from existing data.
Let’s look at both elements in turn.
Collect the Data
The key word here is ‘learning’ and that requires data. Lots of it.
The more the system learns from its database of human face images, the quicker and more accurate the results. Each image in the dataset is appended with a list of attributes describing the person in the image. This metadata can be used to quickly validate or invalidate possible matches suggested by the facial recognition algorithm.
To achieve this, you need a labeled machine learning data set: a curated and annotated collection of examples that can be used by a machine learning system to provide trial-and-error feedback and foster productive learning.
Each of the photos in the dataset will be appended with metadata that specifies the real contents of the photo, and that metadata is used to (in)validate the guesses of a learning facial recognition algorithm.

(Source: Microsoft Azure Face Identification Demo)
Run the Data Through an Algorithm
There are several different algorithms used to turn the guesses of a still-learning facial recognition program into “learned” modifications to the program itself.
For example, Principal Component Analysis (PCA) enables the rapid feature extraction of a face’s key features by reducing the huge, complex dataset used to describe a face to a much-reduced series of key vectors.
Each group of vectors creates an ‘eigenface’. A series of eigenfaces is combined with a basic facial template to produce a much-simplified model of the face that still retains the meaningful properties of the full facial dataset.
It doesn’t take many eigenfaces to achieve a good approximation of most faces. And because the model consists of a list of values, one for each eigenface in the database used, storage space is greatly reduced, and processing time vastly accelerated.
Naïve Bayes classifier is a machine learning model based on probabilities that’s used for classification task. The crux of the classifier is based on the Bayes theorem, and it assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature.
For example, the average a face is round with an average circumference of 55 cm for females and 57 cm for males. Even if these features depend on each other or upon the existence of the other features, all these properties independently contribute to the probability that this image is of a face and that is why it is known as ‘Naive’.
Generative Adversarial Networks (GANs) are an example of the neural network technology driving the latest advances in facial recognition. A GAN pits one neural network against another in a process that allows the system to ‘understand’ the data to such a level it can generate new examples of its own based around the original dataset.
This high degree of deep learning has been demonstrated by a GAN system creating a completely new facial image after analyzing a series of portrait paintings. The GAN’s portrait sold at Christies for $432,000.

(Courtesy: Christie’s)
These deep learning solutions have brought facial recognition well into the 21st century.
The State of Facial Recognition Technology
That explosion in facial recognition uses has sparked a real need for large and comprehensive new image and video data to train the machine learning systems to meet the incredible demand for AI products.
Facial recognition is used in several different areas, including:
- Unlocking your mobile device
- Security systems for airports, banks, retail stores
- Social media – Facebook uses an algorithm to spot faces when you upload a photo to its platform
When your phone unlocks because it recognizes your face, it’s using a basic approach to image analysis that was first invented via deep learning.
The market now uses a mixture of local facial recognition processes that run on a device itself and remote ones that require the sort of computing horsepower that’s usually only available via the cloud.
Microsoft has an easy-to-use middleware solution AI emotion analysis, so just about anyone can work advanced sentiment analysis into their projects.

(Source: Microsoft Azure Emotion API)
In the dash to build these solutions, some companies are starting to go with the lowest bidder and running into issues like rushed image quality which can dramatically impact learning efficiency.
Poor-quality datasets can also introduce biases to the final product. For example, facial recognition technology is already being used to help with searches for criminal suspects and with judgement of job interviewees.
The sheer power of these machine learning products is beginning to put privacy advocates on edge, raising questions about the potentially abusive uses of facial recognition technology that could passively identify any person from a grainy security camera feed.
Addressing racial bias within face recognition and its applications is necessary to make these algorithms equitable and even more impactful, as argued by a recent study from Harvard University.
So where are we headed?
The technology has progressed to the point that its continued development is necessitating updates to law and urgent public conversations. This is the case with all revolutionary new technologies: they create, or threaten to create, a collection of new and unforeseeable problems, which leads to justified cultural anxiety.
From the printing press to e-commerce, what has kept these innovations from having the feared impact has always been continued development directed by a robust public conversation.
The future remains bright for a technology with more than adequate levels of both funding and public interest. With constantly evolving abilities and limitations, there is no telling where it could be in a decade’s time, but it will be exciting seeing how it gets there.
Get the Data You Need to Improve Facial Recognition Applications
The success of any facial recognition technology depends on the quantity and quality of image data used to train it. Many examples are needed, and for each one, a large variety of images are required to build a robust understanding of the face.
This is where Summa Linguae Technologies can help.
SLT’s image collection and data solutions empower all types of facial recognition technology to identify, recognize, and process images with stunning accuracy and speed.
We have an off-the-shelf eye gaze data set available for multiple genders and races. We can also collect images customized to your specific use case.
To get the best from your facial recognition technology, contact Summa Linguae today.


