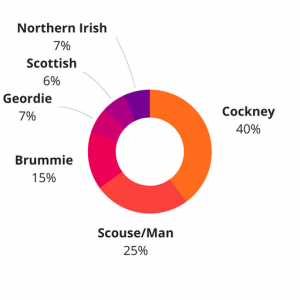
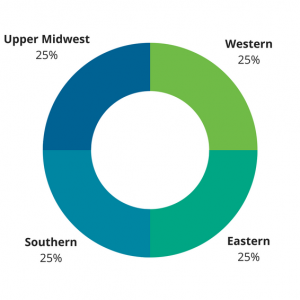
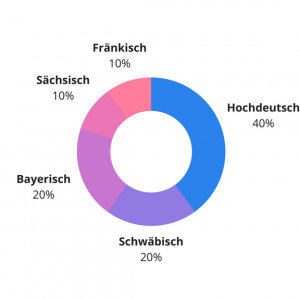
Sonos
Case Study: Dialect & Accent Speech Data Collection
Sonos is one of the world’s leading sound experience brands. As the inventor of multi-room wireless home audio, Sonos innovation helps the world listen better by giving people access to the content they love and allowing them to control it however they choose.
They make it easy to set up a sound system across rooms and to integrate consumer audio devices. This means managing the audio, from music to your TV, centrally.